Overview
Introduction
obsinfo is a Pure Python system for creating FDSN-standard metadata files (StationXML)and standardizing/specifying data processing workflows for ocean bottom seismometers. Instrumentation and stations are specified in text-based information files in YAML or JSON format.
The basic philosophy of obsinfo is:
break down every component of the system into “atomic”, non-repetitive units (Dont Repeat Yourself)
Follow StationXML structure where possible, but:
Add entities missing from StationXML where necessary
Specify units for each component
Allow full specification of stations using text files, for repeatibility and provenance
Object Model
obsinfo uses several layers of information files, which are linked to each other. Most obsinfo users will only use subnetwork files (the purple boxes below), which provide network and station information.
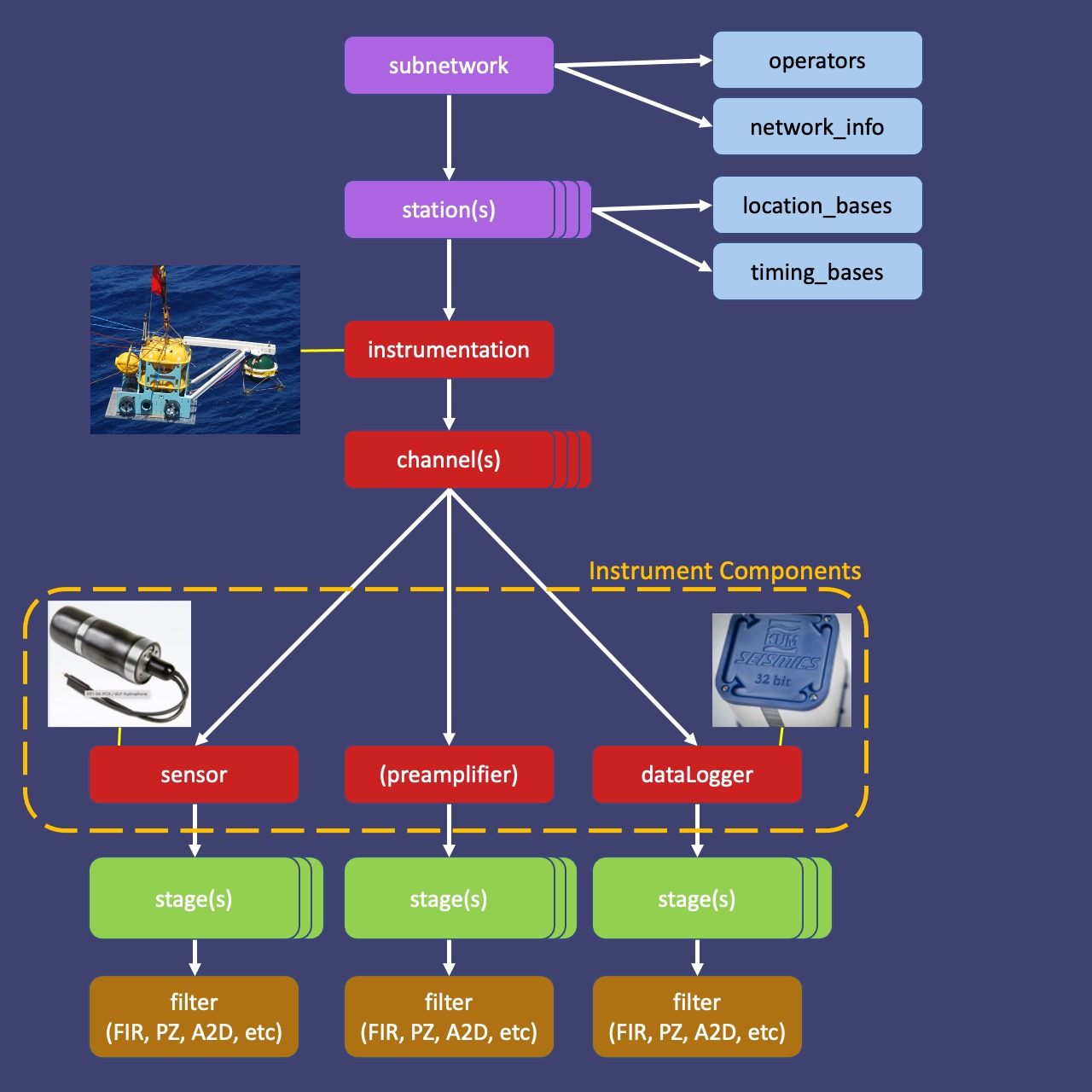
Information Files
obsinfo inputs information files in JSON or YAML format, and outputs StationXML files.
There are 5 main information file types:
Type |
Description |
Filled by |
When filled |
|---|---|---|---|
Deployed stations, their instruments and parameters |
OBS facility |
after a data collection campaign |
|
Instrumentations (OBSs) |
OBS facility |
new/changed instrumentations |
|
|
Components of a single channel |
OBS facility -or- component manufacturer |
new components or calibrations |
One component stage (a sensor, an analog filter/gain, an A/D converter, decimation filters..) |
OBS facility -or- component manufacturer |
new components or calibrations |
|
Specific filter used in a single stage single stage |
OBS facility -or- component manufacturer |
new components or calibrations |
There are 5 other types that allow you to store commonly used/repeated information in one place: timing_base, operator, person, location_base, network
Only the subnetwork files contain deployment-specific information. For most data collection campaigns, they are all you’ll need to fill out.
File Names
Information files should use the following naming convention:
{NAME}.{type}.{format}
where
{NAME}is chosen by you, and should succintly indentify the object.{type}is one of the information file types{format}is one ofyml,yaml,jsnorjson(preferably the 4-character version)
Using these conventions allows obsinfo to perform informative error-checking.
Examples:
TI_ADS1281_FIR1.stage_base.yamlis a filename for a stage of a Texas Instruments FIR filter, written in YAML format.BBOBS.INSU-IPGP.subnetwork.jsonis a filename for a subnetwork of broad-band stations deployed by the INSU-IPGP OBS facility, written in JSON format.
Schemas and Templates
You will find annotated schemas for each file in the Schema files document.
You will find templates for each file in the Templates document.
You can generate a file containing the complete syntax using the command
obsinfo template (see the tutorial on Building a subnetwork file for an
example using subnetwork files).
File Hierarchy
Each information file can access files in a reference directory (the DATAPATH). We recommend the following structure, for compatibility between implementations:
├── persons
├── timing_bases
├── networks
├── operators
├── timing_bases
├── location_bases
├── instrumentation_bases
├── datalogger_bases
│ └── stage_bases
│ └── filters
├── preamplifier_bases
│ └── stage_bases
└─── sensor_bases
└── stage_bases
└── filters
JSON References
Within each file, you can load information from another file using the JREF syntax. For example,
author: {$ref: "../persons/Wayne_Crawford.person.yaml#person"}
substitutes the content of the element person within the file
../persons/Wayne_Crawford.person.yaml into the authors element
of the current file.
Removing the #{element} suffix
If the element name is the same as the file {type}, you can omit
the #{element} anchor:
author: {$ref: "../persons/Wayne_Crawford.person.yaml"}
This is not standard JREF syntax, but it makes files easier to read.
File Metadata
All information files can contain the following top-level elements:
format_version:[REQUIRED] - Version of obsinfo for which this file was writtenrevision:- Who wrote this file and when.date:- date of revisionauthors:- a list of authors of this document
notes:- a list of text strings which provide information which will not be put into the StationXML file.
Added elements
The following obsinfo elements are not found in StationXML. They allow the user to inject important information into StationXML, or to enter information in simpler format.
Element |
Goal | Integration into StationXML |
||
|---|---|---|---|
|
Specify clock drift and/or | Station-level |
||
Simplify entering a digital gain that has no filtering |
Coefficients with empty numerator and denominator |
||
Simplify entering an analog gain that has no filtering |
PolesZeros with empty poles and zeros |
||
Enter an A/D converter based on its voltage and count ranges |
Coefficients with empty numerator and denominator. Gain is calculated and compared with the stage gain. |
||
|
Add extra parameters not specified in obsinfo |
Station-level |
|
|
Add extra parameters not specified in obsinfo |
Channel-level |
|
Resources
For the YAML specification, see YAML . For a tutorial, see YAML Tutorial . For linting and validating YAML files, see YAML Validator
For the JSON specification, see JSON . For a tutorial, see JSON Tutorial For linting and validating JSON files, see JSON Validator
For the JREF notation, see JREF Notation
For the StationXML specification, see FDSN StationXML Reference